
Figure
This blog serves as a practical example of how to implement the LLM-as-a-judge pattern using the Databricks and MLflow ecosystem. Please note that due to NDA limitations, the specific use cases described here reflect a modified process; however, they utilize the exact same underlying technologies, scorers, and architectural principles used in high-stakes production environments.
In the evolving landscape of AI-driven insurance, the transition from static automation to Agentic AI represents a paradigm shift in how carriers manage risk. However, before an organization can consider deploying an autonomous underwriting agent, it must satisfy the non-negotiable Core: a foundation of enterprise-grade cybersecurity, PII masking, and pristine data lineage. You should ensure these prerequisites are in place so that policyholder data remains clean, encrypted, and compliant.
This framework assumes those foundational elements are active and focuses specifically on the next frontier of quality assurance: LLM as a Judge.
In high-stakes insurance risk assessment, traditional rules-based engines are no longer sufficient to monitor the nuanced reasoning required for complex risks. You should implement the LLM as a Judge concept as a secondary, high-reasoning oversight layer designed to evaluate, score, and validate the logic of primary insurance agents. By leveraging the Databricks and MLflow ecosystem, you can move beyond simple binary checks to a sophisticated system of heuristic evaluation that ensures every coverage decision is grounded, logical, and fully auditable.
The Strategic Architecture
To ensure the system is robust, you should deploy three distinct agent personas to simulate a high-performing underwriting department:
The Orchestrator (The Manager): Implement the Orchestrator as the brain of the operation. When a new submission or complex claim arrives, it must break the task into sub-components, such as:
“What is the total insured value and geographic concentration?”
“Are there specific exclusions in the underlying treaty?”
“Does this risk fall within our current Risk Appetite Statement?”
The Specialist Agents (The Workers): You should ground these agents with specific tools. Unlike a standard LLM, these specialists must call specific Unity Catalog functions. To calculate a probable maximum loss, they should pull raw data from historical loss runs and run a deterministic script. This eliminates the “smooth lie” risk where AI creates plausible but incorrect actuarial figures.
The Evaluator (The Judge): Deploy the Judge as an independent AI layer (using MLflow Evaluate) that does not participate in the decision. Its sole responsibility is to grade the other agents. You should configure it to compare the final underwriting summary against the “gold standard” of company guidelines and raw data sources to ensure every risk factor is cited and verified.
Risk Mitigation by Building Safety-First AI
In insurance, “I don’t know why the AI denied coverage” is a massive regulatory and legal liability. You should focus on two primary risk vectors:
Eliminating Hallucinations through Grounding
The greatest risk is the fabrication of facts about a property or claimant.
The Guardrail: Forbid the AI from using its internal knowledge for risk statistics.
The Check: You should run an MLflow Scorer for a “Faithfulness” check. If the Agent claims a building has a new roof, the Judge must verify that the roof replacement actually appeared in the uploaded inspection PDF. If not, the file should be instantly flagged for human review.
Solving the Black Box with Tracing
Regulators require a clear audit trail for adverse actions. You should use MLflow Tracing to record every “thought” the agent had.
- The Mitigation: Create a chain-of-thought log. If an auditor asks why a premium was loaded, the carrier must be able to produce a report showing exactly which tool was called, which line of the loss history was read, and how the Judge scored that specific logic.
Quality Assurance via LLM as a Judge
Utilize the Databricks/MLflow Scorer framework to automate the QA process using rubric-based Scoring. You should configure the Judge to evaluate agents on a 1–5 scale across four key dimensions:
Adherence: Did the agent address all mandatory hazards required in the Underwriting Manual?
Accuracy: Do the loss figures in the summary match the source loss runs?
Tone: Is the assessment objective and professional, avoiding bias?
Safety: Did the agent ignore prompt injection attempts by an applicant trying to hide risk factors?
Human-in-the-Loop (HITL) Triggers
AI should assist, not replace, senior underwriters. You should establish clear Escalation Thresholds:
The Gray Zone: If the Judge provides an accuracy score below 4/5, you should automatically divert the case to a human expert.
Complexity Trigger: Any policy with a limit above a specific threshold should require human sign-off after the AI completes the heavy lifting of data synthesis.
The Production-Ready Governance Process
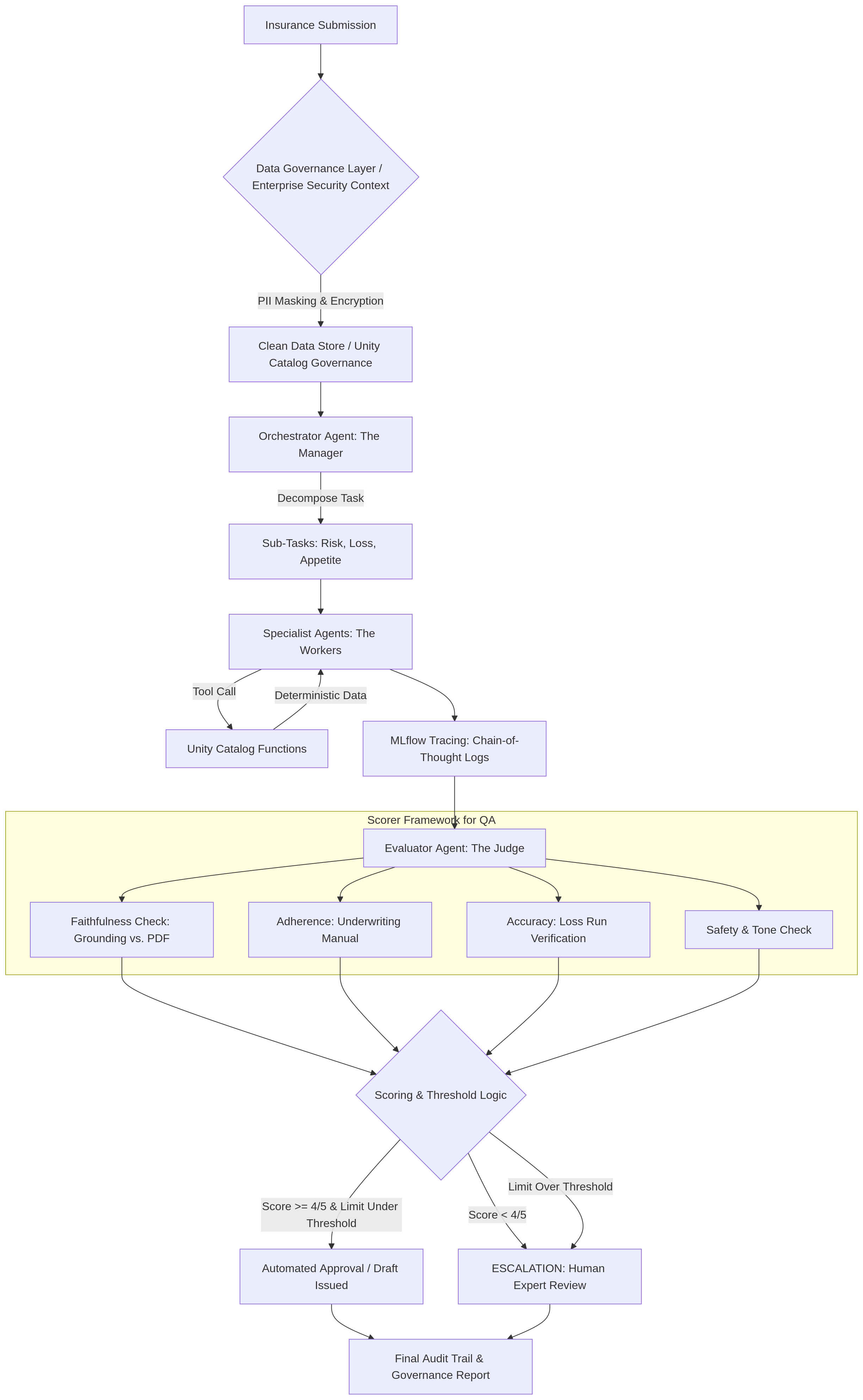
Moving from a conceptual prototype to a live underwriting environment requires a systematic governance model that integrates evaluation at every stage of the submission lifecycle. The following process flow demonstrates how these safeguards are implemented in a production-ready environment:
The Underwriting Submission Lifecycle
The process operates as a multi-stage funnel designed to filter out errors through automated and human checkpoints:
Secure Ingestion & Preparation: Submissions enter through a governance layer where PII masking and encryption are applied to ensure data remains compliant within the enterprise context.
Orchestrated Execution & Grounding: The system decomposes the submission into specific sub-tasks, such as risk and appetite assessment. Specialist agents execute these tasks by pulling deterministic data from verified functions to prevent actuarial hallucinations.
Trace-Level Monitoring: During execution, the system captures a “Chain-of-Thought” log, recording every internal reasoning step and tool interaction for full observability.
Automated Scorer Evaluation: The evaluation layer applies a standardized scorer framework to the captured logs to perform four primary checks.
Dynamic Routing & Escalation: Based on the scoring results, the system applies threshold logic. Cases with high-quality scores and low limits proceed to automated drafting, while low scores or high-complexity risks are automatically escalated for human expert review.
Final Audit & Archival: The process concludes with a comprehensive governance report that archives the trace, the score, and the final decision, providing a transparent audit trail for regulators.
This process transforms subjective “vibe checks” into objective, repeatable metrics. By maintaining these scorers consistently from development through production, the organization ensures that every autonomous decision is grounded in actuarial reality and enterprise security standards.
Process Flow
The Governance-by-Design Future
The primary hurdle for AI in insurance isn’t the technology, but it is the trust. By using an agentic approach on a platform like Databricks, you can create a system that is inherently accountable. The Judge agent ensures the Workers stay within the lines, and the Manager ensures business logic is followed. You should adopt this defense-in-depth strategy to meet the requirements of high-risk AI deployments.