
City
There is a simple truth in cybersecurity that everybody agrees with, yet many organisations still fail to operationalise effectively:
“You can’t build a meaningful CMDB without reliable Asset Discovery.”
CMDB initiatives often begin with ambitious goals like better governance, smoother audits, clearer ownership, improved change management, but they frequently underdeliver. The reason is almost always the same: the data feeding the CMDB is incomplete, inconsistent, or outdated.
This article is a practical guide for organisations modernising their CMDB approach, showing why Asset Discovery is not an optional add‑on but the foundational building block for a successful CMDB implementation.
CMDB Without Accurate Asset Discovery Is a Beautiful Theory with No Grounding in Reality
Many organisations treat the CMDB as a static catalogue. But a CMDB is not meant to be a better-looking spreadsheet, it is intended to be the logical single source of truth for IT and security.
This vision collapses instantly when:
- assets are missing
- ownership is inaccurate
- environments change faster than the CMDB
- cloud resources appear and disappear dynamically
- identities act as assets but are not inventoried
- vulnerability scanners cannot match findings to configuration items
The result is predictable:
- The CMDB becomes a “nice‑to‑have” instead of a strategic system.
- Security teams stop trusting it.
- Auditors challenge it.
- Operations teams ignore it.
Asset Discovery as the Foundation Layer
A modern CMDB depends on three qualities:
- Completeness: it must capture all relevant assets.
- Accuracy: records must reflect reality.
- Freshness: data must update continuously.
Asset Discovery enables all three. If discovery is incomplete, the CMDB is blind. If it is outdated, the CMDB is misleading. If it is inconsistent, the CMDB is fragmented.
Without modern Asset Discovery, a CMDB is little more than a manually curated wish list.
Why Asset Discovery Is Hard in the Cloud Era
In traditional datacenters, discovery was challenging but achievable. In cloud and hybrid environments, it is impossible to do manually and impractical without automation.
Cloud dynamism
Cloud resources:
- scale automatically
- exist only for seconds (containers, jobs)
- vary widely across providers (Azure/AWS/GCP)
- change properties continuously Only real‑time or near‑real‑time discovery can keep up.
Identities as assets
Modern environments rely heavily on:
- service principals
- managed and workload identities
- cloud roles
- machine identities These identities have permissions, can be abused, and directly affect security posture, yet many CMDBs do not track them.
CMDB model vs. modern architectures
Traditional CMDBs expect servers and network devices. Cloud introduces:
- serverless services
- storage accounts
- Kubernetes clusters
- ephemeral compute
- managed databases
- PaaS/SaaS services
- policy/configuration objects CMDBs can model these, but only if discovery supplies the correct data.
What Modern Asset Discovery Looks Like
Organisations succeeding with CMDB implementations have modernised Asset Discovery around these principles:
Cloud‑native, API‑first discovery
Native cloud tools provide rich metadata:
- Azure Resource Graph
- AWS Config
- GCP Asset Inventory
These sources represent reality far better than traditional scanners.
Hybrid agentless + agent‑based model
A CMDB requires:
- agentless discovery for breadth
- agents for OS‑level, configuration, and vulnerability data
Together, they create a high‑fidelity inventory.
Identity‑aware discovery
Modern discovery includes:
- identities and permissions
- trust relationships
- privilege assignments
- service account behaviour Identity is now both an asset and an attack surface.
Data normalisation before writing to CMDB
A robust discovery process:
- normalises cloud metadata
- enforces naming standards
- validates tagging
- resolves duplicates
- establishes a consistent asset identifier
Without consistent IDs, CMDB‑driven automation fails.
CMDB as the “Truth Layer” But Only When Discovery Works
A modern CMDB is not a passive repository. It should power:
- vulnerability management
- secure configuration baselines
- risk scoring
- incident response
- dependency mapping
- governance
- licensing and cost workflows
- cloud posture management
- identity governance
But it can only do this when discovery provides:
- complete data
- consistent data
- continuously updated data
Common Pitfalls When Integrating Asset Discovery Into CMDB
The issues most frequently seen:
- Customising the CMDB core schema → breaks upgrades and integrations.
- Writing raw, unnormalised data → creates duplication and taxonomy conflicts.
- Treating cloud assets like servers → leads to inaccurate modelling.
- Weak tagging or identity governance → poor data quality from the start.
- Inconsistent asset identifiers → the biggest cause of mapping failures.
Best Practices for Making Asset Discovery the Foundation of CMDB
- Let CMDB be the destination, not the discovery engine.
- Enforce tagging and metadata governance to ensure quality.
- Use cloud‑native discovery as the primary input.
- Standardise identifiers across systems to prevent mismatches.
- Automate validation and reconciliation for sustainable quality.
- Integrate discovery into workflows
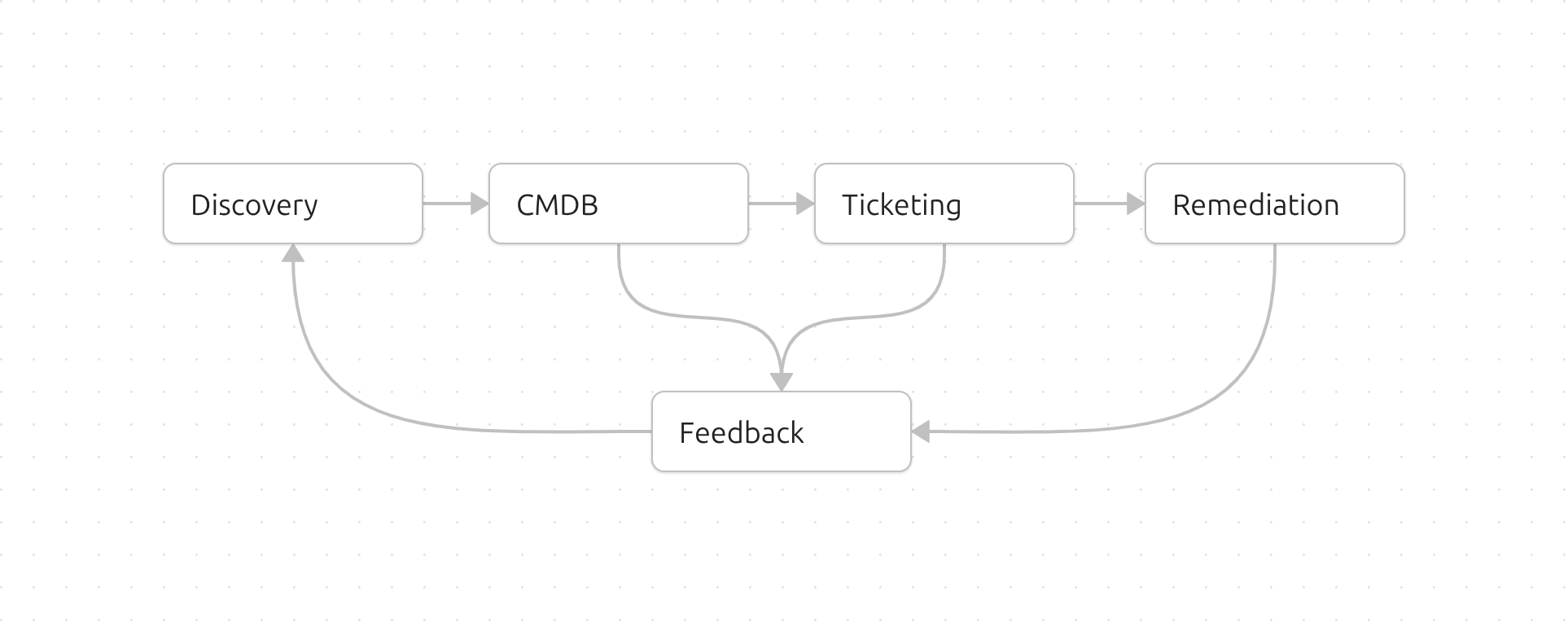
Asset Discovery Flow
Final Thoughts
Modern organisations increasingly depend on their CMDB for security, compliance, and operational decision‑making. But the CMDB can only be as strong as the data foundation beneath it. Asset Discovery provides that foundation ensuring that what the CMDB shows is not a theoretical model of the environment, but an accurate, living reflection of reality.